Failure Modes and How to Diagnose Them
Part 0 — Foundations
"Failure in a well-designed system is rarely noise. It is a signal, sharp and specific, pointing at the assumption that was wrong."
Context
Wednesday morning, post-incident review. The agent issued a refund without checking the cap. The room's first reaction is uniform: "the model hallucinated." The on-call engineer pulls up the trace and stops the conversation: "the model didn't hallucinate. The trace shows the model emitted the right tool call. The Guardian wrap wasn't bound on this code path." The failure was in the manifest, not the model; in the architecture, not the agent.
That moment — re-attribution from "the AI is broken" to "our architecture is broken" — is what this chapter exists to teach. The instinct to attribute failure to the model is strong, comfortable, and almost always wrong in the way that matters; correctly diagnosing the failure determines whether the fix is wait for the next model (stuck) or amend the spec / tighten the manifest / add a CI guard (actionable now).
Your system has produced a wrong outcome. An agent did something incorrect, harmful, or off-target. The instinct is to fix the immediate symptom and move on.
Don't. Every failure in an agent-mediated system carries diagnostic information that, read correctly, prevents a class of future failures. The discipline is: categorize first, fix at the right level, and capture the lesson in a versioned artifact.
This chapter sits in Part 0 — Foundations because the seven-category fix-locus taxonomy is referenced from every Part — scenarios in Frame, Specify, Delegate, and Validate all categorize failures by Cat 1–7, and the closed-loop discipline in Part 5 ships its amendments to the artifact each Cat names. You read it before your pilot runs, not after — knowing the failure taxonomy in advance is how you anticipate where to put oversight, what constraints to add to the spec, and what to log. You return to it during Validate (and during every other phase), when actual failures need categorizing.
The Problem
When an agent produces a wrong output, the instinctive response is attribution: "the AI hallucinated," "the agent misunderstood," "the model got confused." This attribution is often wrong in the way that matters. It locates the failure in the agent, and it is not actionable.
If the failure is the agent's, the only fix is a better agent — wait for the next model. The team is stuck.
If the failure is in the architecture around the agent, the fix is available now. The spec was incomplete. The skill was stale. The oversight model didn't catch the error in time. The tool description was ambiguous. These are fixable without waiting for anyone.
This is not a claim that model-level failures never occur — they do, and the sixth category below names them. (A seventh category, Perceptual Failure, addresses a class of failure specific to perceiving-then-acting systems such as computer-use and browser-use agents.) But teams that systematically categorize their agent failures find that the majority of consequential ones trace back to architectural gaps rather than model limitations. The discipline of failure analysis prioritizes the fixable categories first, because they are the most actionable.
Forces
- Attribution instinct vs. architectural diagnosis. When agents fail, the instinct is to blame the model. Architectural failures (spec gaps, tool gaps, oversight gaps) are more common and more fixable.
- Quick correction vs. root-cause analysis. Patching the output is faster than diagnosing the failure category. But patching without diagnosis means the same failure recurs.
- Model limitations vs. specification gaps. Some failures are genuinely model-level. Others look model-level but are actually spec gaps. Differentiating requires systematic diagnosis.
- Individual failure vs. compounding failure. A single agent failure may be trivial. Failures that compound across steps or agents produce dramatically wrong outcomes.
The Solution
The diagnostic test
Before reaching for the taxonomy, apply this test to every failure:
If a perfectly competent agent had executed this spec exactly as written, would the outcome have been correct?
- If yes — the problem is in execution, not intent. Diagnose and fix the execution layer.
- If no — the problem is in the spec. The spec was incomplete, ambiguous, or wrong. Fix the spec first; then re-execute.
- If you can't answer — the spec is too ambiguous to reason about. That's itself an intent failure: a spec that cannot be evaluated against an outcome has not specified anything.
This test is simple. Applying it rigorously is not. It requires being willing to locate the problem in your own specification — in the thing you wrote — rather than in the tool that executed it.
How this taxonomy relates to the empirical literature
Two academic taxonomies are worth knowing before you adopt this one:
MAST (Multi-Agent System Failure Taxonomy) — Cemri et al., 2025, Why Do Multi-Agent LLM Systems Fail? — empirically analyzes 200+ failure traces across multi-agent systems and partitions failures into three top-level categories (specification issues, inter-agent misalignment, task verification failures) and 14 fine-grained sub-categories. MAST is the most rigorous practitioner-facing failure partition currently published. If you are running a multi-agent system, read it.
The agent-hallucination taxonomies — Zhang et al. (arXiv:2509.18970) and the broader 2024–2025 literature on tool-call hallucination, planning hallucination, and instruction-following inconsistency — give finer-grained partitions of what this chapter calls Category 6.
How the seven categories below differ from those. This chapter's taxonomy is organized by fix locus — which artifact (the spec, a tool, a scope clause, an oversight checkpoint, a model choice, a perception-verification step) you change to prevent recurrence — rather than by failure mechanism. Both partitions are useful; they answer different questions. If you want to understand failure mechanics empirically, use MAST and the hallucination literature. If you want a triage protocol that maps each failure to the artifact a human will edit, use the seven categories below. They are complementary, not competing.
The book takes the practitioner-friendly partition because the discipline it teaches is "fix the right artifact." If your team has the bandwidth to maintain a finer empirical breakdown alongside, do.
The seven failure categories
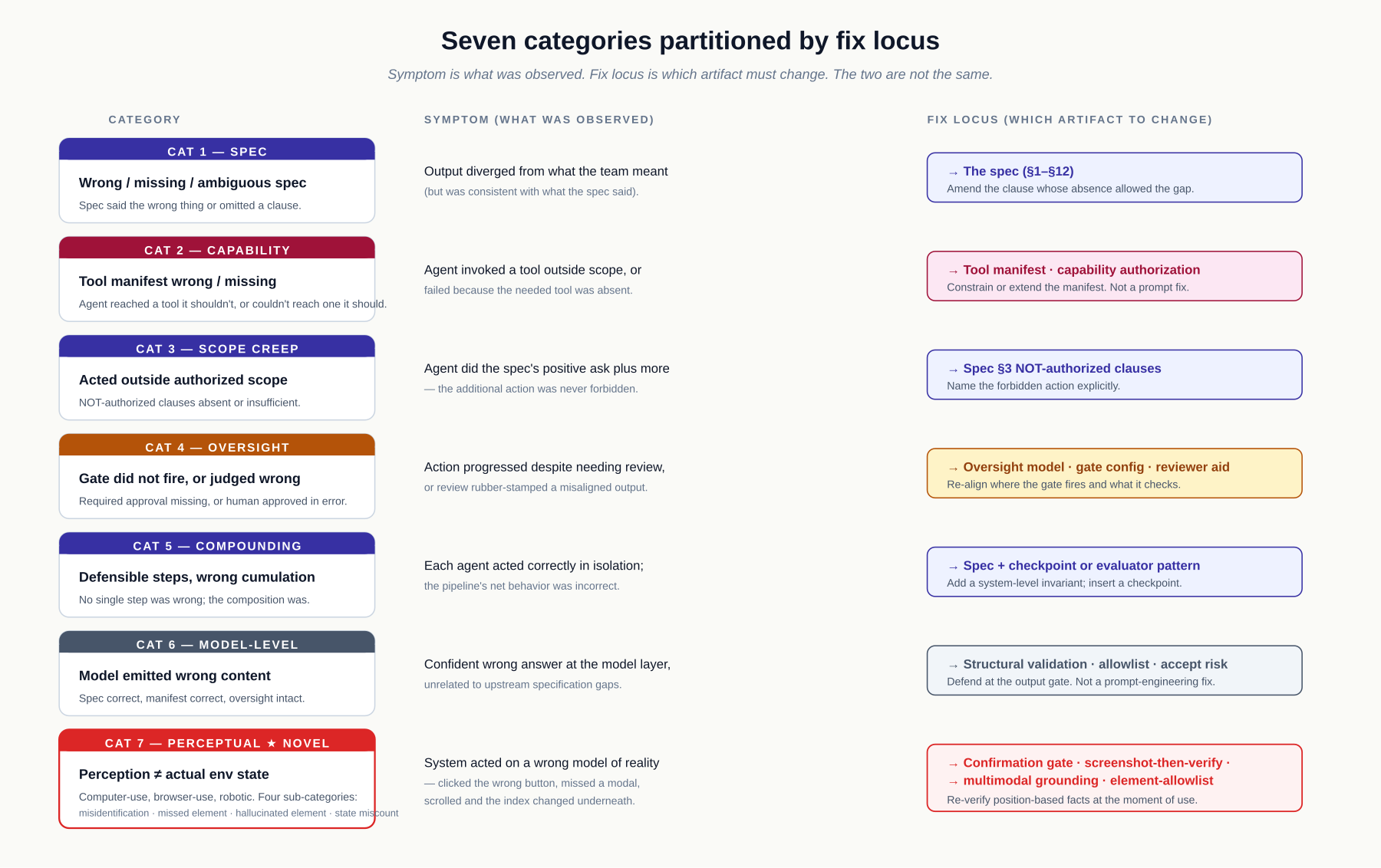
Failures fall into seven categories. Categories 1–6 cover the failure space common to text-based agent deployments. Category 7 (Perceptual Failure) addresses an additional surface that emerges in perceiving-then-acting systems — computer-use agents, browser-use agents, robotic systems — and which prior taxonomies do not partition. Correctly categorizing a failure determines how to fix it — and what it reveals about the design.
Category 1: Spec Failure
The specification was incomplete, ambiguous, contradictory, or incorrect. The agent executed faithfully against the spec it was given, but the spec did not describe the correct output.
Signs:
- The agent did something reasonable given what it was told
- A reviewer who only saw the spec would not have predicted the problem
- The same spec, re-run, produces the same problem
- Different agents or models produce the same wrong output from the same spec
Common manifestations:
- Agent makes a decision the author would have prohibited if they had thought of it
- Agent handles an edge case in a reasonable but incorrect way
- Agent produces the right structure with the wrong content because content requirements were unstated
- Agent stops at the wrong point because completion criteria were vague
Fix: Update the spec. Re-run. Do not patch the output without fixing the specification — the same gap will produce the same error on the next execution.
Category 2: Capability Failure
The agent lacked a tool it needed, or had a tool that was insufficient for the domain (wrong interface, missing data, incorrect behavior). The agent routed around the limitation in a way that was incorrect or incomplete.
Signs:
- The original task was achievable; the agent found a workaround that technically completes the spec but in the wrong way
- The output is subtly wrong in a way that's hard to trace to a specific spec violation
- Often manifests as a long chain of simple tool calls substituting for one appropriate complex tool
Common manifestations:
- Agent manually constructs a complex SQL query instead of calling a report API, getting edge cases wrong
- Agent uses a file system tool to simulate a database operation it didn't have a proper tool for
- Agent approximates a computation by composing simpler operations, losing precision
Fix: Add the missing capability. This is an infrastructure fix, not a spec fix. Once the capability exists, verify the spec would have used it correctly.
Category 3: Scope Creep Failure
The agent completed the requested task and then continued, doing adjacent work that wasn't asked for. Or it interpreted "complete the billing report" to include "fix the data anomalies I found in the underlying records," because fixing them seemed helpful and wasn't explicitly prohibited.
Signs:
- The core task is complete and correctly done
- Additional work was done that nobody asked for
- The additional work may itself be correct, but authorization was absent
Why it matters: scope creep failures are the most likely to cause governance incidents because the agent was doing something it had no authorization for, even if the action was technically correct. The authorization gap — not the quality of the work — is the problem.
Fix: Update the spec's NOT-authorized section to explicitly prohibit the adjacent category of work. This is a scope boundary fix. Review the spec for other potential adjacent work it didn't anticipate.
Category 4: Oversight Failure
The agent produced a wrong output, the oversight model failed to catch it before consequences landed, and the error became known through downstream effects rather than validation.
Signs:
- The error is real (not a matter of preference), but it had time to propagate
- A human reviewer who saw the output at the right moment would likely have caught it
- The oversight model either didn't have a human reviewing at the right stage, or the review didn't catch the specific class of error
Common manifestations:
- Agent sent an external communication before human review (oversight model didn't require pre-send review)
- Agent deployed a change that passed automated validation but violated a convention no test checks
- Agent's minor error accumulated across 200 records before someone noticed
Fix: Redesign the oversight model. This is an escalation trigger / checkpoint fix. The fix is not "be more careful" — it's a structural change to where human attention is applied in the execution flow.
Category 5: Compounding Failure
An early error created conditions for a later error; the combination produced a result neither error would have produced alone. Common in multi-step agent tasks and multi-agent pipelines.
Signs:
- The final output looks extremely wrong
- Tracing backward reveals a chain: each step was locally plausible given what came before
- Any single step's error, if caught early, would have prevented the cascade
Common manifestations:
- Agent produced a slightly wrong plan in step 1; subsequent steps executed correctly against the wrong plan; by step 8, the output is dramatically incorrect
- Agent A produced output that Agent B interpreted in an unexpected way; Agent B produced output that triggered an unintended action in Agent C
- Agent's approximate calculation in step 3 was within tolerance; multiplied by 10,000 records in step 7, the tolerance accumulated past acceptable range
Fix: Two fixes. First, the spec or capability gap that produced the original error. Second, a checkpoint review at the most critical compounding point — typically the handoff between phases or agents.
Category 6: Model-Level Failure
The agent's underlying model produced incorrect output despite a correct, complete spec, appropriate tools, and proper scope. The failure originates in the model itself — its training data, its reasoning patterns, or its instruction-following limitations.
Signs:
- The spec is correct and complete — a knowledgeable human reviewing the spec would have predicted the correct output
- The same spec produces incorrect output consistently or intermittently across re-executions
- The error is not traceable to a missing tool, a scope violation, or an oversight gap
- Output may be structurally correct but factually wrong, or violate constraints clearly stated
Common manifestations:
- Agent hallucinates data values (names, dates, numbers) despite clear spec constraints against fabrication
- Agent systematically misinterprets domain-specific terminology even with skill files providing correct definitions
- Agent produces outputs that pass structural validation but contain subtle logical errors reflecting training biases
- Agent's confidence is uncorrelated with accuracy — high-confidence outputs are wrong at similar rates to low-confidence outputs
Fix: Model-level failures cannot be fixed through better specs alone. Response depends on frequency and severity:
- Low frequency, low severity — accept as residual risk; rely on validation to catch. Document in the spec gap log as a known model limitation.
- Low frequency, high severity — add automated output validation that checks the specific failure pattern. Add human review checkpoint for the affected output type.
- High frequency — the task exceeds the model's reliable capability boundary. Options: narrow the scope to a subset the model handles reliably, switch to a more capable model, retain the task for human execution, or accept that the agent is not deployable in this domain at this time.
Be honest about the limit. This is the category where the framework reaches its boundary. A perfect spec executed by an unreliable model still produces unreliable output. Validation cannot catch every hallucination, especially the high-confidence ones — research consistently shows that LLM confidence is poorly correlated with accuracy. Sampling-based validation will miss failures in the unsampled fraction. Judge models can themselves hallucinate, and they share systematic errors with the agent they are evaluating when both are based on the same model family.
The framework's contribution here is diagnostic, not curative: by ruling out Categories 1–5, teams avoid two opposite errors — blaming architecture for model limits, and blaming models for architectural gaps. But once you have correctly identified a Category 6 failure with high frequency, the honest answer is sometimes "this task is not currently deployable to this agent, regardless of how well we spec it."
Category 7: Perceptual Failure
The system's perception of the environment diverged from the environment's actual state, and the system acted on the wrong perception. This category is specific to perceiving-then-acting systems: computer-use agents, browser-use agents, and robotic systems. Prior taxonomies (MAST, the hallucination literature) do not partition this surface as a distinct class.
Signs:
- The agent acted on something that was not actually there, or acted on the wrong instance of something that was
- A screenshot or sensor record taken at the moment of action would have shown a discrepancy from the agent's claimed reasoning
- The same spec, with the same authorized scope and the same tools, produces correct behavior in some environments and incorrect behavior in others — environment-shape, not spec-shape, is the differentiator
Four sub-categories:
- Misidentification. The agent identifies an interface element correctly as a category (e.g., "a button") but assigns it the wrong role (e.g., a "Cancel" button identified as "Confirm"). The fix is structural: a confirmation gate before high-consequence actions, where the gate's prompt is generated from the agent's claimed intent ("you are about to click Confirm — is that what you mean?") and surfaces the discrepancy to a human reviewer or a Guardian.
- Missed element. The agent fails to perceive an element that is visually present (a modal dialog, an error banner, a required field). The fix is screenshot-then-verify: before any consequential action, the agent re-grounds on a fresh screenshot and reconciles its planned action against what is currently visible.
- Hallucinated element. The agent acts on an element that is not present in the rendered DOM but that the vision-language model believes it sees. The fix is an element-allowlist plus DOM-grounded verification: every claimed element must resolve to a DOM node before action is permitted.
- State miscount. The agent is correct about elements but wrong about position or count (clicks the third row when the second was intended; processes 9 of 10 records and reports 10). The fix is re-verification of position-based facts at the moment of action rather than at the moment of planning.
Common manifestations:
- Lookalike-domain navigation (homoglyph or subdomain confusion) where the agent's visual reading of the URL bar diverges from the actual destination
- Visual instruction injection on a rendered page (text rendered to look like an instruction is treated as authoritative)
- Modal popup interception where an adversarial dialog is processed as a legitimate prompt
Fix: Perceptual failures are not fixed in the prompt. They are fixed at the structural-controls layer — sandboxed environment, authentication-scope minimization, domain allowlist, high-consequence confirmation gates — and at the verification protocol layer — confirmation gate, screenshot-then-verify, multimodal grounding, element-allowlist, DOM-grounded verification, re-verification at action time. None of these live in the agent's instructions; all live in the spec's authorized scope, the tool manifest, or the per-action verification step.
When Cat 7 applies. Cat 7 is the load-bearing diagnostic category for any deployment where the agent's input includes a perceptual layer — vision, audio, sensor — that can diverge from the underlying state. Text-only agent deployments do not encounter Cat 7. Computer-use deployments encounter it routinely; browser-use deployments encounter it whenever the page is rendered rather than parsed; robotic deployments encounter it whenever the sensor reading is the input to the action.
The diagnostic protocol
When a failure occurs, resist the impulse to fix immediately. Apply this protocol:
1. Reproduce the failure deliberately
(If it can't be reproduced, this is likely Category 6)
2. Apply the diagnostic test:
"If a competent agent had executed this spec as written,
would the outcome have been correct?"
3. Walk the categories in order:
- Would a reviewer who saw only the spec have predicted this? → Cat 1: Spec
- Did the agent route around a missing or insufficient tool? → Cat 2: Capability
- Did the agent do correct adjacent work it wasn't authorized? → Cat 3: Scope creep
- Did the error propagate past where review should have caught? → Cat 4: Oversight
- Did one early error compound through later steps? → Cat 5: Compounding
- Spec correct, tools correct, scope correct, but model wrong? → Cat 6: Model-level
- Did the agent's perception of the environment diverge from
the actual state, and was the action taken on that wrong
perception? (Computer-use / browser-use / robotic only) → Cat 7: Perceptual
4. Trace to the specific artifact:
- Spec → which section, which missing or ambiguous clause?
- Capability → which tool call, what was attempted, what was the limit?
- Scope creep → what adjacent action, where was the boundary?
- Oversight → at what point in execution did the error exist and go unreviewed?
- Compounding → where in the chain did the first error occur?
- Model-level → what specific model behavior? Reproducible? Known limit?
- Perceptual → which sub-category (misidentification, missed element,
hallucinated element, state miscount), and which structural
control or verification step is missing?
5. Fix the artifact, not the output
6. Log the gap (see The Spec Gap Log below)
7. Re-execute with the fixed artifact and verify the fix prevents the
failure category, not just the specific symptom
The spec gap log
Every diagnosed spec failure should be recorded in a Spec Gap Log. Not a bug tracker (which tracks implementation errors) — a record of every time a failure pointed to something that should have been in the spec but wasn't.
A Spec Gap Log entry captures:
- What was missing
- When it was discovered
- Which spec section was affected
- What spec change was made
Over time, the log becomes:
- A source of constraint additions that make future specs more complete
- A record of tacit knowledge that was made explicit
- Training data for the team's calibration of "what needs to be in a spec"
- Evidence for governance conversations about where oversight should be increased
This is what it means to say failure is a design signal: each failure, properly diagnosed, makes the system of specs stronger. The goal is not zero failures — it is zero unlearned-from failures.
Common spec failure modes
Within Category 1 (Spec Failure), a few recurring shapes show up so often they're worth naming:
- The Missing Invariant — an assumption so obvious to the author that it was never written; the agent violated it.
- The Scope Ambiguity — the spec didn't define what was out of scope; the agent built too much.
- The Implicit Audience — the spec was written assuming the agent shared the author's cultural and institutional context; it did not.
- The Success Vacuum — the spec had no measurable success criteria; the agent optimized for something that wasn't what was meant.
- The Frozen Context — a constraint in the spec was true at time of writing but is no longer true; the system continues to enforce a rule that no longer applies.
If you find yourself diagnosing the same shape repeatedly, it's a signal that your spec template or review process should explicitly check for it.
Anti-patterns in failure response
- Spec debt. Fixing the output without fixing the spec that produced it. The output is now correct; the spec will produce the same problem on the next execution. Spec debt accumulates until addressed — at which point the fixes are much more expensive, because the gaps have multiplied and the context has been forgotten.
- Oversight theater. Adding more oversight after a failure without fixing the underlying cause. "We'll have a human review every output from now on" is not a fix — it's a compensating control that adds cost without eliminating risk, and creates a false sense of security.
- AI attribution evasion. Blaming the model for failures that are architectural. "The AI got it wrong" is true in a narrow sense and useless in a design sense. The model produced the most probable output for the inputs it received. Fix the inputs.
- Tooling over specification. Investing in better observability, logging, and dashboards while the underlying specs remain under-specified. Observation infrastructure makes failures visible; it does not prevent them. Fix the spec first; build the visibility layer to verify the fix held.
Failure as organizational learning
The most valuable property of a well-structured failure is that it is specific. A failed output, properly diagnosed, points precisely at the assumption that was wrong — and that assumption, now corrected, will be correct for every future execution against the same class of task.
This is the compounding return on spec-driven development: every diagnosed failure improves a spec or a skill, and that improvement is durable. It lives in a versioned artifact applied to every future task in the domain. The organization gets smarter about each class of work as that work accumulates failures and those failures are properly attributed and corrected.
Compare this to a conversational agent workflow: failures are addressed in the conversation ("try again, but this time…"), and the correction lives only in the conversation history. It does not propagate. The organization forgives the failure without learning from it.
The Spec Gap Log, the skill review cycle, and checkpoint adjustment processes are how agent systems turn failure into institutional knowledge. They transform a cost — the failure — into an investment.
Resulting Context
After applying this pattern:
- Failure analysis becomes a structured discipline. Seven categories with a diagnostic protocol replace ad-hoc blame attribution with systematic root-cause identification.
- Fixable failures are distinguished from model limitations. Categories 1–5 are fixable through better specs, tools, scope definitions, or oversight. Category 6 requires model-level responses. Category 7 is fixable through structural controls and verification steps at the perception–action interface.
- Spec gap logs accumulate organizational learning. Each diagnosed failure enriches the team's understanding of what specs need to specify.
- Compounding failures become preventable. By identifying the earliest error in a chain, checkpoint reviews can be placed at the most critical juncture.
Therefore
Agent failures fall into seven categories — spec, capability, scope creep, oversight, compounding, model-level, and perceptual (for perceiving-then-acting systems) — each with a distinct mechanism, a specific architectural fix, and a different lesson. Diagnose before you fix. Fix the artifact, not the output. Log the gap. Re-execute. Failures attributed to "the AI" are unactionable; failures attributed to their architectural category are fixable, and the fixes are durable.
References
- Cemri, M., et al. (2025). Why Do Multi-Agent LLM Systems Fail? — MAST: A Multi-Agent System Failure Taxonomy. — Empirical 14-category partition derived from 200+ multi-agent failure traces; the strongest published practitioner-facing failure taxonomy.
- Zhang, Y., et al. (2025). LLM-based Agents Suffer from Hallucinations: A Survey of Taxonomy, Methods, and Directions. arXiv:2509.18970. — Fine-grained partition of model-level (Category 6) failures.
- Where LLM Agents Fail and How They Can Learn from Failures. (2025). arXiv:2509.25370. — Failure-mode-driven self-correction in agent systems.
- Reason, J. (1990, 1997). Human Error / Managing the Risks of Organisational Accidents. — The Swiss-cheese model and the active-vs-latent failure distinction informing this chapter's "log the gap, fix the artifact" discipline.
- Ohno, T. (1988). Toyota Production System: Beyond Large-Scale Production. — Origin of the "5 Whys" practice that the diagnostic protocol simplifies.
Connections
This pattern assumes:
This pattern enables:
- The Living Spec — failure-driven spec evolution as practice
- Proportional Oversight — designing oversight that catches the failure categories you can't prevent
- Four Signal Metrics — measuring spec quality through failure signal
- Evals and Benchmarks — the empirical layer that complements the diagnostic protocol
- Post-mortem Through Intent — a worked example of this protocol applied to a real incident