Introduction
A Field Guide to Designing and Shipping AI Agent Systems
Why this book exists
Most teams adopting AI agents discover the same pattern within a quarter:
- The first demo is fast and impressive. The second pilot is slower than expected. By the third, the team is debugging output instead of shipping outcomes.
- Architectural coherence quietly degrades because no one is reviewing what the agent decided to do — only whether the test passed.
- The "AI made a mistake" incident reveals that nobody actually agreed, in writing, what the agent was authorized to do, what it must never do, or who was supposed to catch it when it drifted.
- Adding agents made the team faster on individual tasks and slower at shipping reliable systems. The bottleneck moved, but nobody renegotiated the work to match.
This is a structural problem, not a model problem. The model is doing what it was told. The trouble is that being told — what we ask of the agent, what we forbid it, how we check what it did — is the part the team did not learn how to do.
This book is the discipline that addresses that gap. It is a field guide for the people writing the spec, building the agent, and owning the on-call pager when something breaks.
What is the Architecture of Intent?
The framework's one-page definition lives in Part 0 — Foundations, What is the Architecture of Intent?: three questions every delegated system has to answer; five activities that answer them (Frame · Specify · Delegate · Validate · Evolve); three properties that make this an architecture rather than an art (intent as a designed artifact; fixes live in structure, not prompts; calibration is deliberate). Read that chapter once; come back when you get lost.
For the visual version of the same content, see The framework on one page below.
The framework on one page
The five activities and every load-bearing list in the framework — five archetypes, four calibration dimensions, twelve spec sections, eight pattern categories, four oversight models, seven failure categories, four signal metrics — fit on a single page. The canvas below is that page, with each construct in the activity row where it does work. The rest of the book elaborates this picture; when you get lost, return here.
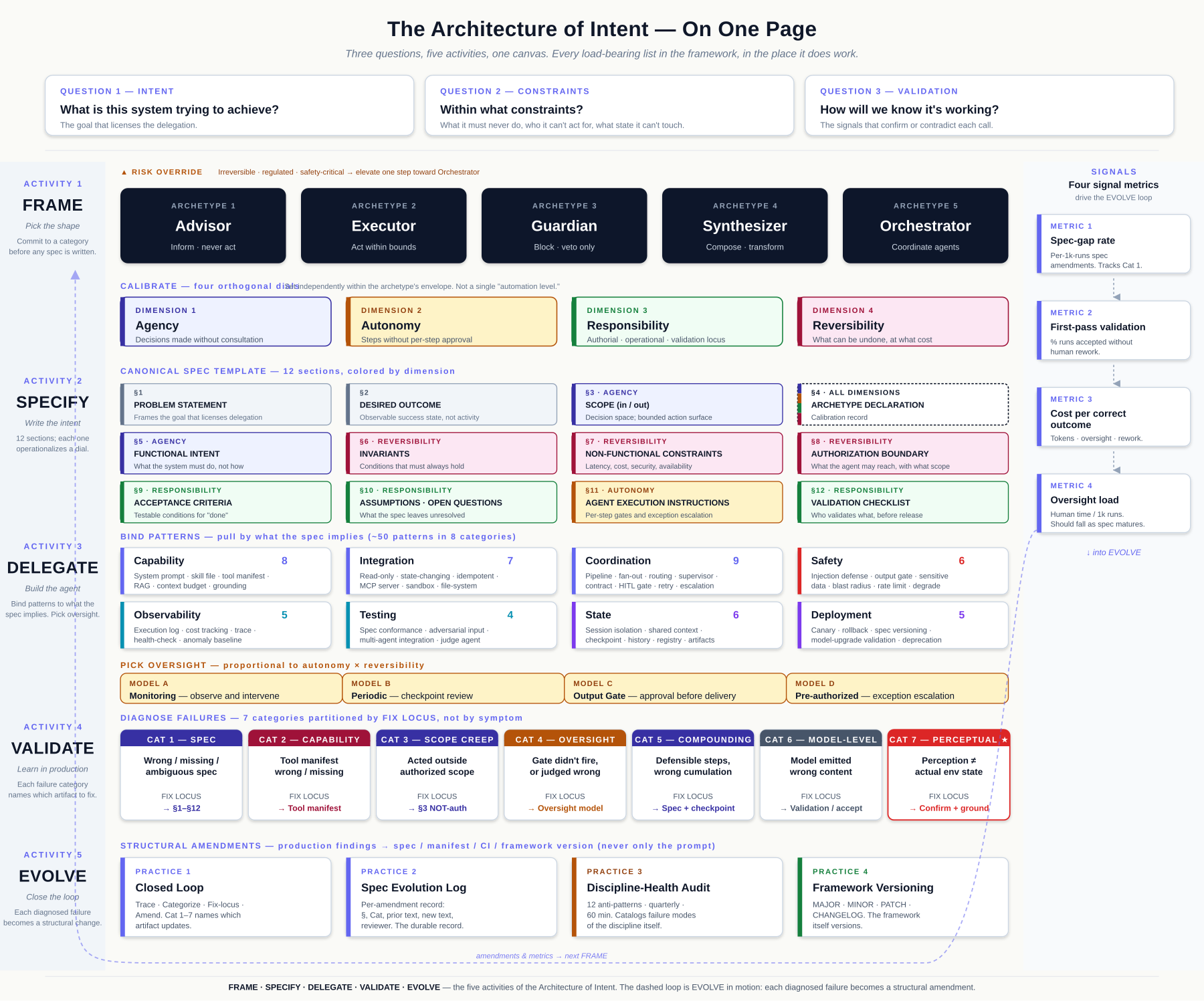
The book is organized around the five activities, with a sustaining-operations layer that runs alongside them. Part 1 — FRAME stands up the archetypes, the four dimensions, and composition first-class. Part 2 — SPECIFY stands up the canonical spec template, the Composition Declaration and Cost Posture sub-blocks, the Intent Design Session, and the repertoires. Part 3 — DELEGATE stands up agent classes, capability and tool-manifest patterns, MCP, oversight, and the patterns that bind to what the spec implies. Part 4 — VALIDATE stands up failure diagnosis (the seven Cats), the four signal metrics, evals, red-team protocol, and the safety / observability / testing patterns that emit the validation signal. Part 5 — EVOLVE stands up the closed loop, the anti-pattern catalog, framework versioning, the Minimum Viable Architecture of Intent, and the deployment patterns (canary, rollback, spec versioning, model-upgrade validation, deprecation) — what changes about the system over time as diagnosed failures become structural amendments. Part 6 — OPERATIONS is not a sixth activity; it is the sustaining layer that runs alongside the five — governance cadence, cost and latency engineering, cacheable prompt architecture, production telemetry, the Adoption Playbook, and DevSquad mapping and co-adoption. The activity count stays five; Part 6 collects the ongoing-ops chapters that previously sat inside Part 5 and now have room to be reference-grade rather than spine narrative. Part 7 — REFERENCE is the catalog: cross-cutting coordination and state patterns, code standards, and the appendices.
Each of Parts 1–5 ends with three short in practice chapters that walk one of three running scenarios — a customer-support agent, a coding-agent pipeline, and an internal docs Q&A agent built by a DevSquad team — through that activity. You can read the book linearly by phase, or follow one scenario end-to-end across all five activities; the in practice chapters cross-link both ways.
What you will have at the end
A pilot you can defend. Concretely, the artifact each row of the canvas above should produce by the time you ship:
- An archetype (Frame). A pre-committed answer to "what kind of system is this — Advisor, Executor, Guardian, Synthesizer, or Orchestrator?" — with the agency, autonomy, responsibility, and reversibility profile that follows from that choice.
- A spec (Specify). A written, reviewable artifact in twelve sections that says what the agent must do, what it must never do, what success looks like, and what context it operates in. The agent executes against this. Humans review against this.
- An agent (Delegate). A system prompt, a set of skills, a tool manifest, and a capability boundary that match the archetype, with the cross-cutting patterns (safety, observability, coordination, state) bound to what the spec implies.
- An oversight model (Delegate). A specific answer to "who reviews what, when, and what triggers escalation?" — one of Monitoring, Periodic, Output Gate, or Pre-authorized — proportional to the blast radius of the agent's actions.
- Metrics that mean something (Validate). Four signal metrics — spec-gap rate, first-pass validation, cost per correct outcome, and oversight load — that tell you whether the pilot is healthy without manufacturing a dashboard for its own sake.
- A deployment plan (Validate). Canary, rollback, and spec versioning so you can ship without making the change irreversible.
- A closed-loop discipline (Evolve). A spec evolution log, a Discipline-Health Audit cadence, and an explicit commitment that diagnosed failures produce structural amendments — not prompt patches — so the practice compounds across teams and survives turnover.
If you finish the book and don't have those seven things, the book has failed you. Tell us what was missing.
Who this is for
This book has one primary reader: the tech lead, staff engineer, or platform-team member who is on the hook for an agent system going to production. Everything in the book is aimed at making that person's next decision better.
It is also useful for:
- Architects and principal engineers responsible for the structural integrity of systems that agents now help build. Parts 1, 4, and 5 are most relevant.
- Engineering managers trying to understand what their teams are actually doing when they "use AI." The Prologue and Part 1 give you the vocabulary; Part 5 gives you what to ask for in reviews.
- Platform teams building shared agent infrastructure (MCP servers, spec templates, archetype catalogs). Parts 3, 4, and the Cross-Cutting Patterns section are the spine of your platform.
This book is not a tutorial on a specific AI tool, a survey of the model landscape, or a strategy document about whether to adopt AI. It assumes you've already decided to ship something with agents and now need to do it without regret.
How to use it
Two reading modes, both supported.
Linear. Start at the Prologue and read straight through. Each Part assumes the previous one. By the end you have the full vocabulary and the full pilot kit. Estimated time: 6–10 hours, but that's not how anyone actually reads a field guide. Read a Part, apply it, come back.
Work-shaped. Enter at the decision you're currently stuck on. The Pattern Index and the Glossary are your navigation tools. Common entry points:
| If you are... | Start at |
|---|---|
| Just trying to see the framework applied in one screen | A Miniature Pilot, End-to-End |
| Choosing how to structure a new agent system | Pick an archetype |
| Writing a spec right now | The canonical spec template |
| Designing oversight for an agent that's about to ship | Proportional Oversight |
| Diagnosing a failure | Failure modes and how to diagnose them |
| Setting up safety controls | Safety patterns |
| Walking one running scenario across all five activities | Frame in practice — Customer-support, Coding-agent pipeline, or Internal docs Q&A (DevSquad) |
| Looking at a v1.x worked pilot (legacy) | Legacy v1.x Worked Pilots Archive — superseded by the running scenario chapters above |
What the book does not promise
It does not promise that following these patterns guarantees a successful pilot. Models change, requirements shift, and some failures are genuinely model-level and unfixable by better specs. What this book gives you is the smallest set of structures that make a pilot's failures diagnosable and correctable rather than mysterious.
It does not promise that every pattern applies to every team. Regulated industries (healthcare, finance, defense) have compliance requirements that go beyond what's covered here. Multi-organizational agent systems — where agents from different orgs interact — have governance problems this framework does not solve. Cost-benefit analysis for adopting these practices depends on factors that vary too widely to generalize.
It does not promise to settle every open question in the field. How precise is "precise enough"? What happens when model capability outpaces governance? Can intent engineering scale to truly autonomous systems? These questions are real and unresolved. This book stakes out a working position; treat it as something to test against your own context, not as final word.
Honest scope: what this book is, and what it isn't
This book's strongest contribution is a design vocabulary and a diagnostic discipline: archetypes, the four dimensions, the failure taxonomy, the spec template, the oversight models. Teams that adopt it report that their conversations about agent systems get sharper — which is exactly what you'd expect when a shared vocabulary replaces ad-hoc framing.
It is not a complete technical playbook. Specifically, the book is light on:
- Prompt caching as architecture (covered briefly in Cost and Latency Engineering; deserves more depth for any system at 100+ runs/day).
- Model-tier selection under specific budget and latency constraints — the Model-Tier Quick-Select Card gives a decision matrix; the underlying chapter goes deeper.
- Multi-tenant fleet governance at very large scale — Multi-Tenant Fleet Governance covers the first layer of fleet discipline (constraint inheritance, cross-tenant isolation, partitioned telemetry, platform-tier failure-locus). The framework's working position is that those four moves carry a fleet from one to fifty tenant teams; at hundreds or thousands of tenants, additional infrastructure-organizational machinery is needed that this book does not develop.
- CI/CD wiring details — when does the eval suite gate a merge versus alert versus observe? The disciplines are described; the specific platform integration is not.
Read the book for the vocabulary, the structural patterns, and the failure diagnosis. Bring your own platform expertise for the wiring.
A note on style
This is a working book, not a literary one. Chapters are short, the vocabulary is consistent, and the templates are meant to be copied. Where a pattern can be stated in two pages, it is. Where a pattern needs a diagram, a table, or a worked example, it gets one. There is no philosophical preamble, because the reader of this book is presumed to already be working on the problem and to need the tools, not the argument.
If you want to see the framework applied to one concrete system in one screen before going any further, read A Miniature Pilot, End-to-End next. It is the canvas walked top-to-bottom on a recognizable pilot, with one failure traced back to its fix locus.
If you want the argument for why this discipline matters — what changed structurally about software when code stopped being the bottleneck — read the Prologue instead. It's three pages.
If you'd rather just start with the first decision you have to make, go to Pick an archetype.
Continue to A Miniature Pilot, End-to-End to see the framework applied to one concrete system, or jump to the Prologue for why this work matters.